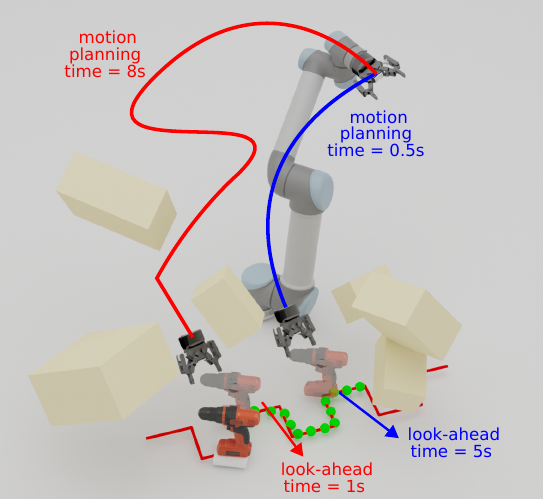
- It can reason about the reachable workspace and through dynamically controlling the look-ahead time and time budget, it maintains the predicted pose and the planned motion within the most reachable region.
- It learns to generate a small look-ahead time when the predicted trajectory is not accurate.
- It learns to produce a small but sufficient time budget for motion planning.
Dynamic Grasping with a Learned
Meta-Controller
What is the problem? Grasping moving objects is a challenging task that requires multiple submodules such as object pose predictor, arm motion planner, etc. Each submodule operates under its own set of meta-parameters. For example, how far the pose predictor should look into the future (i.e., look-ahead time) and the maximum amount of time the motion planner can spend planning a motion (i.e., time budget). Many previous works assign fixed values to these parameters; however, at different moments within a single episode of dynamic grasping, the optimal values should vary depending on the current scene.